Beyond the NAT: CGNAT, Bandwidth, and Practical Tunneling
Home internet in the 90s felt simple. You plugged into Ethernet, got an IPv4 address, and you could expose a service directly. Today the path is layered and driven by economics. IPv4 did not end in a hard way. It became scarce and costly, see IPv4 address exhaustion. Data centers and enterprises still buy and route IPv4. Most residential users are placed behind Carrier-grade NAT (CGNAT) and many providers mix in IPv6 to keep compatibility while lowering costs.
This post maps that landscape with a practical lens. We will move from end to end addressing to provider networks that multiplex thousands of customers behind a few public IPs using NAT. CGNAT saves addresses and reduces ISP costs, but it blocks inbound connectivity, see NAT traversal. It also complicates games, VoIP, and P2P, and makes self-hosting fragile without extra tools.
Bandwidth is often sold as “speed,” yet what matters in practice is capacity, symmetry, and guarantees. Residential links are usually asymmetric and best effort. Business uplinks and servers provide symmetric throughput, static addressing, and a Service Level Agreement. Not every outage comes from a bad actor. Popularity surges can mimic attacks, see the Slashdot effect. Misconfigured bots can overwhelm a small uplink much like a targeted DDoS.
If CGNAT blocks your ports you still have options. Tunneling restores reachability by creating an outbound path to a reachable endpoint, see tunneling protocol. We will set up a simple reverse tunnel with bore-cli. We will also use Cloudflare Tunnel, which gives you an outbound only connection that terminates at the Cloudflare edge with HTTPS. But, remember, always follow your ISP’s terms of service when exposing services through tunnels.
What you will learn
- The path from end to end IPv4 to CGNAT and mixed IPv6 deployments, with links for deeper reading
- Why capacity, symmetry, and SLA matter more than headline Mbps
- How DDoS and self DDoS relate to capacity, not only to malice
- Step by step tunneling examples with bore-cli and Cloudflare Tunnel to bypass CGNAT safely
A Brief Historical Context: From Old Ethernet to Modern Networks
Early home networking felt direct. You plugged into Ethernet, got an IPv4 address, and many apps worked end to end. The original design assumed that any host could reach any other host. That model started to bend as the internet scaled.
1980s to mid 1990s
- IPv4 offered about 4.3 billion addresses. It felt huge for the time.
- LANs spread with Ethernet and hubs, then switches. The goal was simple broadcast domains that were easy to wire.
- The web took off. Every new dial-up or office network needed addresses.
Late 1990s to 2000s
- Address pressure grew. Engineers standardized private ranges in RFC 1918 and popularized NAT.
- ISPs rolled out DSL, DOCSIS cable, and later fiber. Residential links stayed mostly asymmetric. Download first. Upload small.
- NAT fixed scarcity for a while but broke pure end to end reachability. Apps began to ship NAT traversal logic. See STUN, TURN, and ICE.
2010s
- Cellular data and IoT exploded. IPv4 markets formed. Blocks became a real asset with a real price.
- Providers adopted Carrier-grade NAT and the shared space from RFC 6598. The path became device to home NAT to ISP NAT to internet. Often called NAT444.
- IPv6 matured and shipped at scale. It offers a massive address space and restores direct addressing when both sides use it.
Today
- IPv4 is not gone. Enterprises and data centers still route it. They buy or lease blocks when needed.
- Residential users are often behind CGNAT. Many ISPs mix IPv6 with IPv4 to keep costs low and compatibility high.
- Business uplinks and data centers focus on symmetry, static addresses, and SLAs. They also bundle DDoS protection. Residential remains best effort.
Why the split exists
- Economics. Public IPv4 is scarce and priced. Giving one to every home is expensive at scale.
- Support and reliability. Self-hosting from a living room adds operational burden for the ISP. CGNAT reduces inbound trouble tickets.
- IPv6 adoption is uneven. Mixed IPv6 plus IPv4 behind CGNAT is a practical bridge that works with today’s apps.
What this means for you
- If you need inbound reachability from home, plain port forwarding may fail under CGNAT. You will need either a public IP plan, a business link, or a tunnel.
- If you run a service at scale, plan for IPv6 and keep IPv4 working through proxies or tunnels while the world catches up.
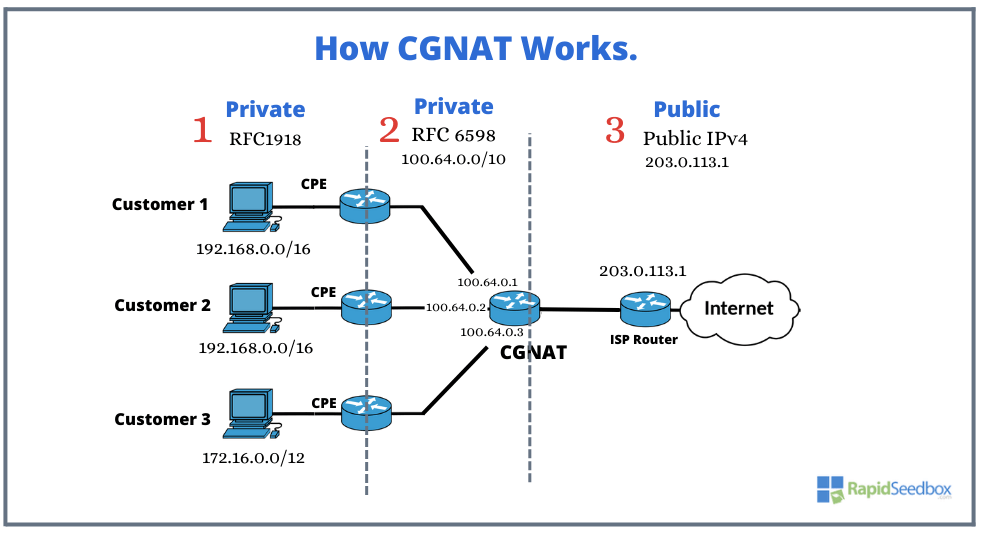
What is CGNAT?
Carrier-grade NAT (CGNAT) puts many customers behind the same public IPv4. Your home router already does NAT inside your LAN. CGNAT repeats that idea inside the ISP so thousands of subscribers can share a small pool of public IPv4 addresses. You can read the formal overview here Carrier-grade NAT.
Why providers use it
- Handing a unique public IPv4 to every household is expensive at scale
- CGNAT stretches IPv4 while ISPs roll out IPv6 for end to end reach where possible
The address spaces in the path
- Your LAN uses private ranges from RFC 1918
10.0.0.0/8•172.16.0.0/12•192.168.0.0/16 - ISP core uses the shared space from RFC 6598
100.64.0.0/10 - Public internet is the small set of public IPv4s that the outside world sees
How it looks on the wire
People call this NAT444. One NAT at home. A second NAT at the ISP. Public internet outside.
What changes for you
- Inbound is blocked by design
Port forwarding on your router is not enough. The second NAT lives inside the ISP and you cannot configure it - State and timeouts matter
NATs track flows. Quiet long lived sessions can drop when tables expire - Per subscriber port limits can apply
Heavy P2P or high fan out apps may hit those limits under load - Hairpin and loopback quirks are common
Accessing your own public hostname from inside the LAN may fail unless the router supports hairpin NAT - Attribution gets fuzzy
Many customers share one public IP. Abuse desks rely on IP plus port plus timestamp - Apps that feel it
Self hosting at home. Some games and VoIP. P2P tools that expect inbound reachability
See NAT traversal for how apps try to cope
How to tell if you are behind CGNAT
- Check what the world sees
Linux/macOS:curl https://ifconfig.me
Windows PowerShell:Invoke-RestMethod https://ifconfig.me - Check the WAN address on your router
If it is in100.64.0.0/10or any RFC 1918 range and it does not match step 1 then you are under CGNAT - Run a traceroute to a public host
Early hops in100.64.0.0/10are a strong hint
Why Bandwidth Matters
People often hear “speed” and think everything is solved by a bigger number. Real performance depends on a mix of capacity, delay, and quality. Start with a few clear ideas
- Bandwidth is the size of the pipe. See Bandwidth in computing
- Throughput or goodput is what you actually move after protocol overhead. See Throughput
- Latency is the time a packet takes to travel. See Latency
- Jitter is how much latency varies. See Jitter
- Packet loss ruins interactive work and large transfers. See Packet loss
The big differences that users feel
- Symmetry
- Residential links are usually asymmetric. Big download and small upload. Examples are ADSL and many DOCSIS plans
- Business fiber and data center uplinks are usually symmetric. Same download and upload
- Guarantees
- Home plans are best effort. No formal uptime or repair time
- Business plans may include a Service level agreement. You get targets for uptime, latency, and support
- Addressing and reachability
- Home plans often sit behind CGNAT with dynamic IPs
- Business and servers can get static IPv4 and IPv6 which helps with hosting and VPNs
- Oversubscription and shaping
- ISPs oversubscribe residential networks. Many homes share the same last mile and upstream capacity
- Providers shape or prioritize traffic during peak hours. Business circuits and data centers usually sit on less contended paths with better peering
- DDoS exposure
- Home users rarely get DDoS mitigation
- Business uplinks and hosting providers often bundle filtering and scrubbing
Why citizens should care
- Video calls, cloud backups, and game streaming need upload. A 300 down and 30 up plan can stall when two backups and one stream run at once
- Latency and jitter decide how games and calls feel. Bufferbloat on cheap routers can add hundreds of milliseconds during uploads
- If you live stream or host small services, the uplink and IP policy matter more than the headline download
Why companies should care
- Remote teams push traffic both ways. CI logs, artifact uploads, and video meetings eat upload
- Backups and data syncs grow with the business. Symmetric capacity and predictable latency keep restore times sane
- Public services need stable addressing and DDoS protection. That points to business fiber or data center hosting
Residential vs business at a glance
Reading a speed test the right way
- Run tests while idle and again while saturating your upload with a large file
- Watch latency under load. Big spikes mean bufferbloat
- Test at different times of day to see contention
- Compare the result with your contract. Many plans advertise “up to” numbers
Practical rules of thumb
- If your work depends on uploading, choose a symmetric plan or move the serving side to a data center
- If you need to be reachable from the internet, ask for static IPs or use tunnels and hosting where static IPs exist
- If voice and video are key, aim for low jitter and low latency first. Raw bandwidth helps only after those are stable
DDoS: More Than Malicious Attacks
A Distributed Denial of Service is any event that overwhelms a target so real users cannot use it. The classic case is an attacker with a botnet that floods your link or your server. The tricky part. Not every outage comes from a bad actor. Traffic that looks hostile can come from success or from mistakes.
When it is not really an attack
- Flash crowds. A post goes viral and a small uplink or a small server collapses. Slashdot effect for example.
- Crawler storms. Many bots hit the same pages at once because of a bad robots policy or a broken sitemap.
- Client loops and retries. Apps retry in tight loops when an upstream is slow. The retries pile up and look like a flood.
- Misconfigurations. DNS or CDN changes that point heavy traffic to a tiny origin. One click turns into a fire hose.
How DDoS shows up on the wire
Think in three currencies.
- Bits per second for link saturation.
- Packets per second for device CPU and interrupt pressure.
- Requests per second for application capacity.
Common patterns to be aware of
- Volumetric floods that fill your uplink.
- Transport floods that abuse TCP state. See SYN flood for example.
- Application floods that hit slow or expensive endpoints.
- Reflection and amplification that bounce traffic off open services. See DNS amplification attack.
Why capacity and design matter
- If the uplink is thin, even a moderate spike can look like a DDoS.
- If your origin is slow or runs heavy queries, small request spikes can take it down.
- If you lack caching and rate limits, bots and users pile up on the same hot path.
First steps when things go sideways
- Check graphs for bps, pps, and rps at the same time. This tells you what kind of pressure you have.
- Look for a single source network vs many. Reflection floods often come from many sources.
- Confirm recent deploys, DNS changes, and promos. You might be seeing your own success.
- Protect users first. Serve a simple static page if the app is melting.
Defensive playbook for citizens and hobby projects
- Put public sites behind a CDN with caching and basic Rate limiting.
- Avoid exposing a home IP. Use tunnels or hosting that gives you clean egress and DDoS shielding.
- If your IP is targeted, power cycle the modem to get a new one if your ISP assigns dynamic addresses. This is not a guarantee.
- Keep the origin light. Cache aggressively. Disable heavy debug endpoints.
Defensive playbook for companies
- Terminate users at an edge that can absorb traffic. Anycast and CDNs help spread load.
- Use a scrubbing service for volumetric events. Many providers can filter and forward only clean traffic.
- Enable Web Application Firewall (WAF) rules and request caps for slow endpoints
- Separate static from dynamic. Cache static at the edge. Protect dynamic with authentication and per user limits.
- Keep an upstream plan for Remotely Triggered Black Hole Filtering (RTBH) and filtering with your transit.
- Test incident drills. Measure time to detect, time to mitigate, and user impact.
How this ties back to bandwidth
- More capacity buys time to react. It does not solve everything.
- Symmetric uplinks protect interactive work when uploads surge.
- SLA backed circuits come with better escalation paths during events.
Quick checklist
- Do I know my normal bps, pps, and rps ranges.
- Do I have caching and rate limits on hot paths.
- Do I have an edge or CDN in front of the origin.
- Do I have a way to drop traffic upstream if the link fills.
- Do I have a simple static fallback ready to serve.
Bottom line
DDoS is a capacity and design problem as much as it is a security problem. Treat it like reliability work. Build headroom. Add smart controls. Plan how to fail in a way that keeps real users moving.
Escaping CGNAT with Tunnels
If you want to expose a local service from behind CGNAT, you need a tunnel. Your machine opens an outbound connection to a reachable host. Traffic arrives on that host and is forwarded back through the tunnel to your app.
Two solid options
- bore-cli. Minimal reverse tunnel that you control end to end on your own VPS. Very good fit for self hosting because you own both sides and can add your own TLS, auth, and logging.
- Cloudflare Tunnel. Outbound connector that publishes your service at Cloudflare edge with HTTPS, DNS, WAF, and Access. Great for quick exposure and edge protection.
bore-cli example
Goal. Expose http://localhost:8000 from your home machine by using a VPS as the public entry.
On the VPS with a public IPv4
# Install with cargo if needed
cargo install bore-cli
# Run the tunnel server on port 2200
bore server --port 2200
Keep the server running. Use tmux or screen, or create a systemd unit if you want permanence.
On your home machine behind CGNAT
# Expose local port 8000 through the VPS
bore local 8000 --to your.vps.example:2200
Ask for a fixed remote port if you prefer stable links
# Request remote port 44321 on the VPS
bore local 8000 --to your.vps.example:2200 -p 44321
Quick test without a VPS
You can try the client against the public server. bore.pub is a shared demo endpoint. Ports rotate and availability is not guaranteed. Use your own VPS for anything beyond quick tests.
bore local 8000 --to bore.pub
Notes
- Bore forwards raw TCP. Good for HTTP, SSH, and databases.
- You decide TLS and authentication at the proxy or the app.
- Public servers like bore.pub are shared. Use them for demos and learning, not for production.
- Reliability comes from owning both ends on a VPS where you can debug and add HTTPS.
Cloudflare Tunnel quick start
Goal. Get a public HTTPS URL for http://localhost:8000 without opening ports.
On the host that runs your app
# Install cloudflared from your package manager or Cloudflare repo
# One shot tunnel for quick sharing
cloudflared tunnel --url http://localhost:8000
Cloudflared prints a trycloudflare.com URL. Share it and you are live over HTTPS. No DNS change needed. Good for demos and tests.
Cloudflare Tunnel with a custom domain
This keeps a stable name and can serve multiple services.
Login and create a named tunnel
cloudflared tunnel login
cloudflared tunnel create myapp
Map a hostname to the tunnel
cloudflared tunnel route dns myapp app.example.com
Add an ingress config at ~/.cloudflared/config.yml
tunnel: myapp
credentials-file: /home/you/.cloudflared/<tunnel-uuid>.json
ingress:
- hostname: app.example.com
service: http://localhost:8000
- hostname: ssh.example.com
service: ssh://localhost:22
- service: http_status:404
Run the tunnel
cloudflared tunnel run myapp
Now you reach your local app at https://app.example.com and SSH at ssh.example.com. Traffic terminates at Cloudflare edge with TLS. Your origin IP stays hidden. You can add Cloudflare Access to require login before requests reach your service.
Which one should you use
- Choose bore-cli if you want reliable self hosting with full ownership. You already have or want a VPS. You prefer simple moving parts that you can inspect and fix. You can add Nginx or Caddy for TLS and auth.
- Choose Cloudflare Tunnel if you want instant HTTPS, a managed edge, DNS integration, WAF, and Access. You trade some control for convenience and protection at the edge.
Safety checklist
- Put authentication in front of admin panels and dashboards.
- Avoid exposing databases directly.
- Watch logs on the VPS or in Cloudflare to confirm only the intended paths are reachable.
- Keep clients and servers up to date and run them as services if you need permanence.
Threat model: who can see your tunnel (and what “encrypted” really means)
A quick thanks to [@than3-bits] for opening [issue #16]. I focused hard on reachability and practicality, and I did not spell out the uncomfortable part: tunneling solves CGNAT, but it also redraws your trust boundaries.
When people say “I’m tunneling,” they often mean three different things at once:
- I can be reached from the public internet
- my ISP cannot see what I am doing
- I am safer now
Only the first one is guaranteed. The other two depend on who you are defending against, and where your traffic actually terminates.
There are two threat classes that get mixed together all the time.
1) AS-level adversaries: the routing layer is part of the threat model
An Autonomous System (your ISP, a regional carrier, a transit provider) can observe traffic patterns and sometimes influence routing in ways that are invisible from your side. The Princeton/ETH RAPTOR line of work is the canonical reference here: routing dynamics and BGP events can put an AS on-path, enable interception and hijack scenarios, and make correlation attacks more feasible than most people assume.
This is not “they can always decrypt TLS.” It is “they can often see who talks to whom, when, and how much, and sometimes they can change the path.” For privacy and anonymity, metadata is not a footnote. It is most of the story.
So if your mental model is “my tunnel means my ISP is blind,” this is where it breaks. Your ISP may not see inside the tunnel, but it still sees the tunnel’s existence, its timing, and its endpoints. If you are trying to hide from an AS-level observer, you are in Tor/anonymity territory, not “practical tunneling” territory.
2) Termination points and PKI: encryption is only end-to-end if you control both ends
Even when content is encrypted, it is only protected up to the point where it terminates.
If you terminate your tunnel on a VPS you do not control, then the VPS provider can see plaintext after decryption (or at least see the decrypted traffic as it leaves that host). That does not require exotic attacks. It is simply the normal consequence of where you ended the tunnel.
The subtler angle is the Web PKI: browsers rely on certificate authorities, certificate transparency, and revocation mechanisms that are not uniformly strict. In many real environments, revocation checking is “soft,” and the ecosystem keeps shifting. The practical consequence is that “a cert was revoked” does not always translate into “clients will hard-fail immediately.”
This does not mean MITM is trivial. It means that if your threat model includes powerful on-path actors with influence over enterprise networks, endpoints, or trust stores, you should not treat the Web PKI as a perfect safety net.
Practical takeaways (what I actually recommend)
-
Be clear about the goal:
- If you want reachability through CGNAT or better routing, a tunnel is great.
- If you want anonymity against network-level observers, a tunnel is not the right tool by itself.
-
Prefer protocols where trust is explicit:
- WireGuard-style designs use static keys and simple trust. If you control both endpoints, you can reason about what is and is not exposed.
-
Treat the tunnel endpoint as sensitive:
- Self-host when you can.
- If you must use a provider, assume the provider is part of your threat model.
-
If you care about metadata leakage:
- Consider multi-hop designs or Tor for the use cases that actually require it.
-
Do not assume “HTTPS” means “no middleboxes”:
- In some real networks, TLS can be inspected at enterprise edges or on managed devices because trust anchors can be added. That is policy and endpoint control, not a cryptography failure.
-
Keep “encryption everywhere” as a baseline, but do not ignore the ugly reality:
- There are still environments where traffic ends up in the clear (satcom/backhaul stories are a reminder), and sometimes the weakest link is upstream, outside your home lab, and outside your visibility.
My Thoughts About SSH and general port openings without tunneling
The safest default is simple. Do not expose SSH on a public IP. Bind SSH to a private network or to a VPN interface and treat public exposure as a last resort.
Default stance
- Disable public SSH on internet facing hosts like dedicated servers or VPS
- Bind the SSH daemon to localhost and to your VPN interface only
- Use keys only. Disable passwords and root login
Example sshd_config with a Tailscale or WireGuard address
# listen only on localhost and the VPN interface
ListenAddress 127.0.0.1
ListenAddress 100.64.12.7 # Tailscale or WG address here
PermitRootLogin no
PasswordAuthentication no
PubkeyAuthentication yes
AllowUsers [email protected]/10 # optional allow list by source
VPN first
- Use a mesh VPN like Tailscale or your own WireGuard. You will get stable reachability without opening ports
- Keep a second path. If Tailscale has an outage you can fall back to WireGuard or an alternate provider
- Document a break glass path. Store the steps in your password manager so future you can recover access fast
If you must expose SSH on the internet
- Restrict by IP with a firewall allow list. Start with your office and home ranges
- Move SSH to a non default port to cut noise. This is not real security. It simply reduces bot scans
- Add Fail2ban or an equivalent tool to throttle guessed logins
- Use multi factor for SSH. FIDO2 hardware keys with the OpenSSH sk key types are a strong option
- Use multi factor for SSH. Prefer FIDO2 hardware keys with OpenSSH “sk” key types
- Example:
ssh-keygen -t ed25519-sk -O resident -O verify-required
- Prefer SSH certificates instead of long lived static keys if you have many users
Example UFW allow list that prefers VPN and blocks the world
# deny all by default
sudo ufw default deny incoming
sudo ufw default allow outgoing
# allow SSH from VPN only
sudo ufw allow from 100.64.0.0/10 to any port 22 proto tcp
# optional. allow a trusted office IP
sudo ufw allow from 198.51.100.27 to any port 22 proto tcp
sudo ufw enable
sudo ufw status verbose
Backups and recovery
- Keep daily backups for your VPS and test restores often
- Follow the 3 2 1 rule. Three copies on two types of media with one off site
- Encrypt backups and protect the keys. Store recovery material separate from the server
- Use provider snapshots for fast rollbacks and a file level backup for real recovery
Hygiene to keep you out of trouble
- Patch the base OS and OpenSSH regularly
- Use minimal users and least privilege. Add sudo with a short timeout
- Watch logs. Send auth logs to a central place or at least to email
- Avoid exposing admin panels. Put them behind the VPN as well
- Rotate keys when people leave. Remove stale users and old authorized keys
TLDR
- Do not expose SSH on a public IP when you can avoid it
- Use a VPN like Tailscale or WireGuard and keep a second path as backup
- If you must expose it use allow lists, keys, Fail2ban, and multi factor
- Back up daily and test restores so a mistake is only an inconvenience